Continuano i nostri articoli dedicati al processamento di serie temporali! Nel secondo articolo della serie abbiamo visto come confrontare sequenze diverse utilizzando il SAX Encoding. Ma se volessimo quantificare la distanza tra due Time Series? A questo scopo, introduciamo un'altra tecnica estremamente utile, il Dynamic Time Warping (DTW).
Il codice di questo articolo è disponibile su un notebook Google Colab.
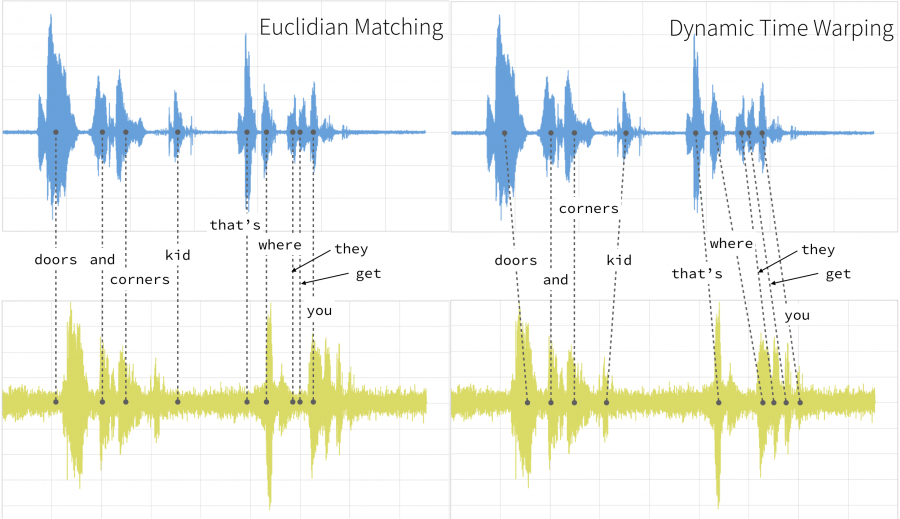
Il Dynamic Time Warping (DTW) è un algoritmo utilizzato per misurare la similarità tra due o più serie temporali, andando a leggere su Wikipedia troviamo la seguente definizione:
"Il Dynamic time warping, o DTW, è un algoritmo che permette l'allineamento tra due sequenze, e che può portare ad una misura di distanza tra le due sequenze allineate. Tale algoritmo è particolarmente utile per trattare sequenze in cui singole componenti hanno caratteristiche che variano nel tempo, e per le quali la semplice espansione o compressione lineare delle due sequenze non porta risultati soddisfacenti."
Che casi d'uso ci suggerisce la definizione? Prendiamo ad esempio il riconoscimento vocale: una persona potrebbe parlare più velocemente o più lentamente della voce campione preregistrata, mentre il DTW non risentirebbe di questo problema, a differenza di una distanza che venisse applicata "punto per punto".
Il DTW è molto utilizzato in ambito IoT dove gli stream di dati proveninenti da video, audio, sensori, possono essere trasformati in una sequenza lineare per essere analizzati con questa tecnica, in particolare è molto efficace con serie ad alta frequenza di campionamento, pensiamo ad esempio al mercato delle utilities o dell'automotive.
L'idea di base è calcolare la distanza tra due vettori/serie storiche indipendentemente dalla loro lunghezza, e per farlo bisogna che i vettori rispettino le seguenti regole:
- ogni indice della prima sequenza deve poter essere confrontato con tutti gli indici delle altre e viceversa;
- il primo indice della prima sequenza deve essere associato al primo indice dell'altra sequenza (ma non deve essere la sua unica corrispondenza);
- l'ultimo indice della prima sequenza deve corrispondere all'ultimo indice dell'altra sequenza (ma non deve essere la sua unica corrispondenza);
- La mappatura degli indici dalla prima sequenza agli indici dell'altra sequenza deve essere monotonicamente crescente. A grandi linee, indipendentemente dalla lunghezza delle serie l'indice iniziale e finale devono coincidere.
Per illustrare il DTW userò in parte un breve esempio con due sequenze di pochi elementi preso da riptutorial.
L'algoritmo di base è molto semplice, vedremo la differenza della similarità tra serie con DTW e distanza euclidea. Partiamo creando gli array:
import numpy as np
serie_1 = np.array([1, 2, 3, 5, 5, 5, 6], ndmin = 2)
serie_2 = np.array([1, 1, 2, 2, 3, 5], ndmin =2)Le due serie hanno lunghezza diversa, quindi un confronto punto per punto con distanza euclidea (o altra distanza) non sarebbe del tutto corretto. Supponiamo che le due serie partano nello stesso periodo e che la serie_2 finisca prima, quindi aggiungiamo un elemento per calcolare la distanza (non rispetta le regole sugli indici del DTW).
\[ d\left( p,q\right) = \sqrt {\sum _{i=1}^{n} \left( q_{i}-p_{i}\right)^2 }\]
serie_2New = serie_2.copy()
serie_2New = np.append(serie_2New, 0)
distance = np.sqrt(np.sum((serie_1-serie_2New)**2))
print(distance)La distanza calcolata è 7.14.
Passiamo ora al calcolo della distanza mediante DTW, per farlo ci servirà una matrice di dimensione $n \times m$ dove $m$ ed $n$ sono la lunghezza della serie più 1.
n = serie_1.shape[1]+ 1
m = serie_2.shape[1]+ 1
DTW = np.zeros([n,m])Il primo elemento della matrice DTW[0,0] deve essere pari a 0, mentre prima riga e prima colonna pari ad infinito. Quanto fatto serve per il cold start dell'algoritmo. Il cold start è il confronto con i periodi precedenti quando si è al primo passo dell'algoritmo, impostando una riga fittizia ad infinito non si incorre in situazioni anomale e si evita di implementare condizioni sullo start che appesantirebbero ulteriormente il calcolo.
DTW[0,1:] = np.inf
DTW[1:,0] = np.inf
print(DTW)
Per ogni posizione della matrice verrà calcolata la distanza euclidea di ogni punto di una serie da tutti i punti delle altre partendo dalla posizione DTW[1,1]. Ad ogni distanza viene aggiunto il minimo tra:
- il valore precedente sulle righe: cancellazione;
- il valore precedente sulle colonne: inserimento;
- il valore precedente in diagonale: corrispondenza.
for i in range(1,n):
for j in range(1, m):
dist = abs(serie_1[:,i-1] - serie_2[:,j-1])
DTW[i,j] = dist + min([DTW[i-1,j], DTW[i,j-1], DTW[i-1,j-1]])
print(DTW)L'algoritmo restituisce una matrice con tutte le posizioni valorizzate. Arrivati a questo punto partendo da DTW[0,0] bisogna costruire un percorso che tocchi il valore minimo più vicino a quello nella posizione in cui ci troviamo muovendoci da sinistra verso destra in orizzontale/verticale/obliquo, questo è il Warping Path.
- Uno spostamento orizzontale significa che serie_2 è accelerata durante questo intervallo.
- Uno spostamento verticale significa che serie_2 è decelerata durante questo intervallo.
- Una mossa diagonale significa che durante questo periodo le serie camminano di pari passo.
Il valore finale del path è la distanza tra le serie. Dalla matrice si nota che il calcolo non è stato influenzato dalla diversa dimensione delle sequenze e che il valore finale è molto più piccolo di quello calcolato punto per punto con la distanza euclidea.

La complessità di calcolo del DTW è $\mathcal{O}(m \times n)$ dove $m$ ed $n$ rappresentano la lunghezza di ciascuna sequenza. Se avessimo sequenze molto lunghe, il confronto tra le due risulterebbe complesso, ed anche inutile, perchè alcuni confronti verrebbero effettuati su posizioni lontanissime. Prendiamo l'esempio della serie storica, vorrebbe dire confrontare periodi molto distanti temporalmente che non hanno nessuna relazione ed influenza tra loro. Per questo motivo viene inserita un parametro $w$, una finestra temporale su cui calcolare le differenze.
La finestra temporale è il valore minimo tra un intero definito dall'utente (io ho utilizzato 1) e la differenza in valore assoluto tra $m$ ed $n$.
w = max([1, abs(n-m)])Di seguito come cambia l'algoritmo per il calcolo della distanza.
for i in range(1,n):
for j in range(max([1,i-w]), min([m, i+w])):
dist = abs(serie_1[:,i-1] - serie_2[:,j-1])
DTW[i,j] = dist + min([DTW[i-1,j], DTW[i,j-1], DTW[i-1,j-1]])
print(DTW)Nell'esempio proposto non si noteranno differenze viste le sequenze molto corte e con una differenza di una sola posizione, ma per sequenze molto lunghe e con differenze di lunghezza evidenti l'impatto è tangibile.
Vista la complessità quadratica del DTW sono stati proposti alcuni migliorameti dell'algoritmo, il più conosciuto è probabilmente il FastDTW. Il FastDTW cerca di migliorare le performance approssimando alcuni risultati, ma non sempre questa riduzione di tempi si traduce in una qualità del risultato accettabile. Ci sono molti paper e package su questo algoritmo, vi lascio il link della libreria Python fastdtw e il paper "FastDTW is approximate and Generally Slower than the Algorithm it Approximates" che spiega in quali casi questo algoritmo sia davvero più performante (mantenendo accettabile l'efficacia) del DTW classico.
Tornando a quanto detto nell'introduzione, come può essere/viene usato il DTW nei problemi di Machine Learning?
- Apprendimento supervisionato, come distanza per algoritmi KNN su Time Series.
- Apprendimento non supervisionato, come misura di similarità nel clustering di Time Series.
- Apprendimento semi-supervisionato, etichettare le Time Series utilizzando un algoritmo di clustering basato su DTW e successivamente classificare secondo queste assegnazioni.
Di seguito un esempio di clustering basato sul DTW.

Ingrandendo il grafico finale si può notare come alcune serie dei cluster B e C sembrino molto più vicine al centroide A in alcuni periodi, ma il DTW non ne risente e permette un raggruppamento migliore.

Lascio alcuni paper del 2020 sull'argomento per chi volesse approfondire:
- Time Series Clustering Model Based on DTW for Classifying Car Parks
- Intertemporal Similarity of Economic Time Series: An Application of Dynamic Time Warping
- Time series classification using local distance-based features in multi-modal fusion networks
- DTW-NN: A novel neural network for time series recognition using dynamic alignment between inputs and weights
- Adaptively constrained dynamic time warping for time series classification and clustering
L'immagine di copertina è presa da https://databricks.com/blog/2019/04/30/understanding-dynamic-time-warping.html.
Se questo articolo ti è piaciuto e vuoi tenerti aggiornato sulle nostre attività, ricordati che l'iscrizione all'Italian Association for Machine Learning è gratuita! Puoi seguirci su Facebook, LinkedIn, e Twitter.